The 291-Story Build Benchmark: How We Measure 100% Pass Rate, Verified Nightly
The benchmark is the contract. Every night, 291 stories run end-to-end through Yeti Build Agent and every one must finish with a deployable artifact, a passing ATF test, and a clean audit.
Why a Benchmark Rather Than a Marketing Number
AI products are easy to demo and hard to trust. A static screenshot says nothing about whether the same prompt works on a Tuesday afternoon, or after a frontier model update, or against a new release of the ServiceNow platform.
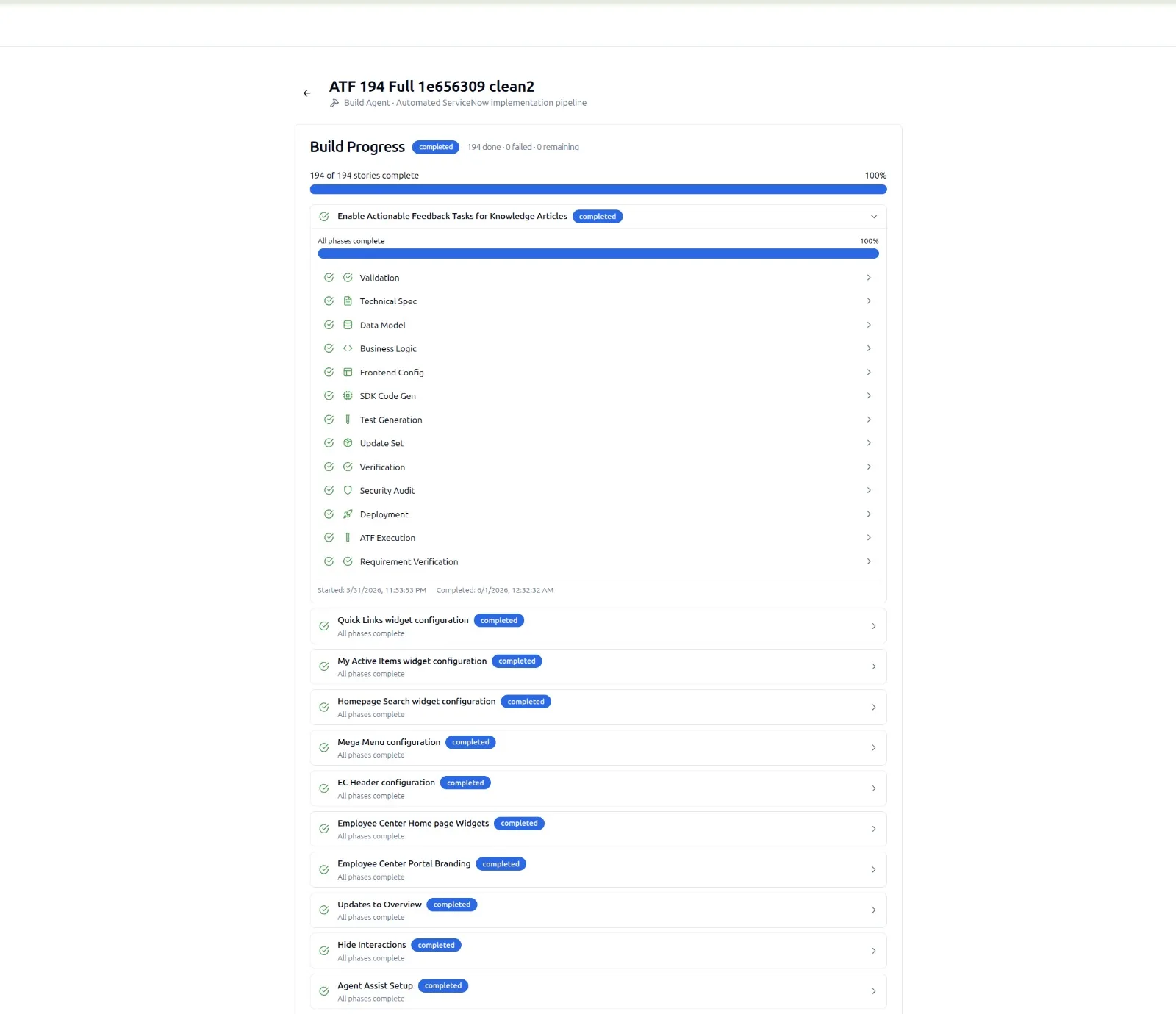
SnowCoder runs a continuous build benchmark to make the trust question answerable with data. The benchmark grew from an early 194-story version to today's 291 stories. Every night the entire benchmark runs end-to-end through the Yeti Build Agent pipeline and every story must reach a clean deployable artifact.
When the benchmark drops below 100%, the regression is investigated and fixed inside SnowCoder before anything ships to customers.
What Counts as a Story
Each of the 291 stories represents a realistic ServiceNow delivery task. They are written in the same form as customer stories: a short narrative, acceptance criteria, and a target instance.
The benchmark covers the full breadth of the Fluent SDK surface, exercising the 42 artifact classes that Yeti Build Agent emits. Examples of story categories:
- Custom tables with reference fields, choice lists, and computed columns.
- Business Rules covering before, after, async, and display timings.
- Script Includes with proper class structure and reuse patterns.
- Client Scripts and UI Policies tied to live form fields.
- Flow Designer flows including approvals and external action calls.
- Scheduled Jobs and Fix Scripts.
- REST integrations with credential management.
- ACL definitions across table, field, and record scopes.
- ATF test suites covering each artifact end-to-end.
Each story has a known correct outcome so the benchmark is binary: pass or fail.
What "Pass" Actually Means
A story passes only when every stage of the pipeline succeeds. There is no partial credit.
- Validation: the story is accepted as buildable.
- Technical Spec: a coherent spec is produced.
- Data Model: required tables and columns are emitted without conflicting with the target.
- Business Logic and Frontend: all generated scripts pass syntax, ServiceNow API, security, and performance validation.
- Fluent CodeGen: the project builds and installs cleanly.
- ATF Testing: every generated test passes against the target instance.
- Update Sets and Verification: the Update Set replays cleanly into a sandbox.
- Security and Script Audit: zero critical findings from the 500+ checkpoints.
- Deployment: the artifact reaches the target instance and the post-deploy smoke check passes.
The benchmark is a 291-by-9 truth table. Anything other than all green is a regression.
How a Story Looks in Practice
A representative benchmark story description and its expected ATF assertion shows how concrete the contract is:
# Story 144
As a change manager
I want a Business Rule that blocks creation of a Change
when the planned start time is in the past
so that we do not log retrospective changes
Acceptance:
- Before insert on change_request
- If start_date < gs.nowDateTime(), abort with a clear message
- ATF: attempt to create a change with a past start date and
assert the abort + error message
Expected ATF assertion:
assertEquals(record.sys_id, '', 'Record should not have been created');
assertContains(errors, 'Planned start cannot be in the past');Story 144 has a known-good output. When Yeti Build Agent produces something different, the benchmark catches it.
The Nightly Cadence
The benchmark runs every night against a clean reference instance on the Zurich release. Each story executes in isolation against a fresh scope so that interactions between stories do not mask regressions.
The pipeline produces a daily report. Pass rate, per-stage timings, and any failures are recorded. The expected output is 291 of 291 stories green. Anything else is a P1.
The cadence is what makes the benchmark useful. A one-off test number ages quickly. A nightly number is current.
How the Benchmark Grew From 194 to 291
The benchmark started at 194 stories covering the original artifact set. As the ServiceNow Fluent SDK surface expanded and as customer feedback identified scenarios that should be covered, the benchmark grew to 291 stories.
The growth is one-directional. Stories are added when they catch a category of failure that was not previously covered. Stories are not retired except in the rare case that a platform capability is replaced by a fundamentally different mechanism.
That means the benchmark always reflects current coverage rather than yesterday's feature set.
Why a Public Number Matters for Buyers
AI vendors typically publish accuracy claims based on private evaluations. The 291-story build benchmark is run continuously and the result is the same for everyone: pass or fail.
For a buyer that means three concrete things. First, the system has a defined contract for what good looks like. Second, regressions are caught quickly because the cadence is nightly. Third, the benchmark grows as the platform and customer expectations grow, so trust does not stagnate.
Read the public benchmark summary at snowcoder.ai/benchmarks.
Related Reading
Run the benchmark mindset on your own backlog
Pick three real stories. Run them through Yeti Build Agent. Compare the output to what your delivery team would have produced.