How AI Should Change Your ServiceNow SDLC: A Practical Playbook
Rebuilding delivery around AI-assisted production, governed review, and measurable quality.
The ServiceNow SDLC is not disappearing. But the cost model behind it is changing.
For years, delivery models were built around a simple assumption: developer time was the constraint. Discovery took days or weeks. Business analysts translated requirements into specifications. Developers hand-built Business Rules, ACLs, UI Policies, Client Scripts, Flow Designer logic, and other platform artifacts. Test creation often came late. Release cycles were slowed by the cost of validation, coordination, and manual review.
AI changes that equation.
Generation is becoming cheap. Specification drafting, technical design, code production, test creation, and remediation can now happen far faster than before. The new bottleneck is not production. It is human review, architectural judgment, security assurance, and release governance.
That means bolting AI onto the old SDLC is not enough. If the delivery model still assumes that every artifact must move through the same manual path as before, the organization caps AI output at human review speed and loses much of the benefit.
The opportunity is to redesign the SDLC around a new operating model:
AI produces. Humans validate. Gates control risk.
The stages remain familiar. The work inside them changes.
The Same SDLC, but with a Different Bottleneck
The five stages of delivery still matter: discovery, design, build, test, and release. AI does not remove them. It changes how each stage operates.
- Discovery. AI drafts the first version of the requirement, acceptance criteria, negative paths, user stories, and edge cases. The business analyst validates the requirement and confirms that it reflects the business outcome.
- Design. AI generates the technical design, including data model implications, access-control assumptions, integration points, and platform patterns. The architect ratifies the design and ensures it fits the enterprise standard.
- Build. The pipeline generates Fluent source: a code-first representation of ServiceNow configuration such as tables, fields, ACLs, Business Rules, Client Scripts, UI Policies, and other metadata. The developer reviews the generated output, handles exceptions, and approves or adjusts the implementation.
- Test. Automated Test Framework coverage is generated alongside the build. Testers no longer spend their time manually writing every test. They review the coverage map, challenge assumptions, and decide whether the test suite is sufficient for the risk of the change.
- Release. A verified update set moves through security checks, script review, destructive-change controls, and deployment gates. The release manager approves based on evidence, not guesswork.
In every stage, humans still have the final word. The difference is that their time is spent on judgment rather than production.

Where People Add Value
AI does not eliminate delivery roles. It changes where those roles create the most value.
- Business Analysts move from writing specs to validating outcomes. They focus on ambiguity, missing scenarios, exception paths, and business logic that AI may not infer. Their value shifts from documentation production to requirement quality.
- Architects move from drawing every design to setting the patterns. They define the rules AI must respect: naming conventions, scope boundaries, table-extension strategy, integration patterns, data model principles, and performance constraints. Their job is to make sure generated designs fit the platform strategy.
- Senior Developers move from primary authors to expert reviewers. They review generated Fluent source, resolve complex implementation issues, approve changes AI cannot confidently infer, and mentor teams on what good looks like.
- Junior Developers move from isolated script authors to pattern-based builders. They learn faster by reviewing generated output, seeing platform patterns repeatedly, and understanding why certain changes pass or fail quality gates.
- Testers move from manual ATF authors to coverage analysts. They focus on whether the generated tests protect the business process, the access model, and the failure paths. AI writes the tests; humans judge whether the coverage is enough.
- Release Managers move from manual movers to gatekeepers. They own the control framework: which changes require deeper review, which audits must pass, and which approvals are needed before production.
The net effect is not simply fewer people. It is better leverage. Senior capacity can stretch across more workstreams because routine production work is no longer the limiting factor.

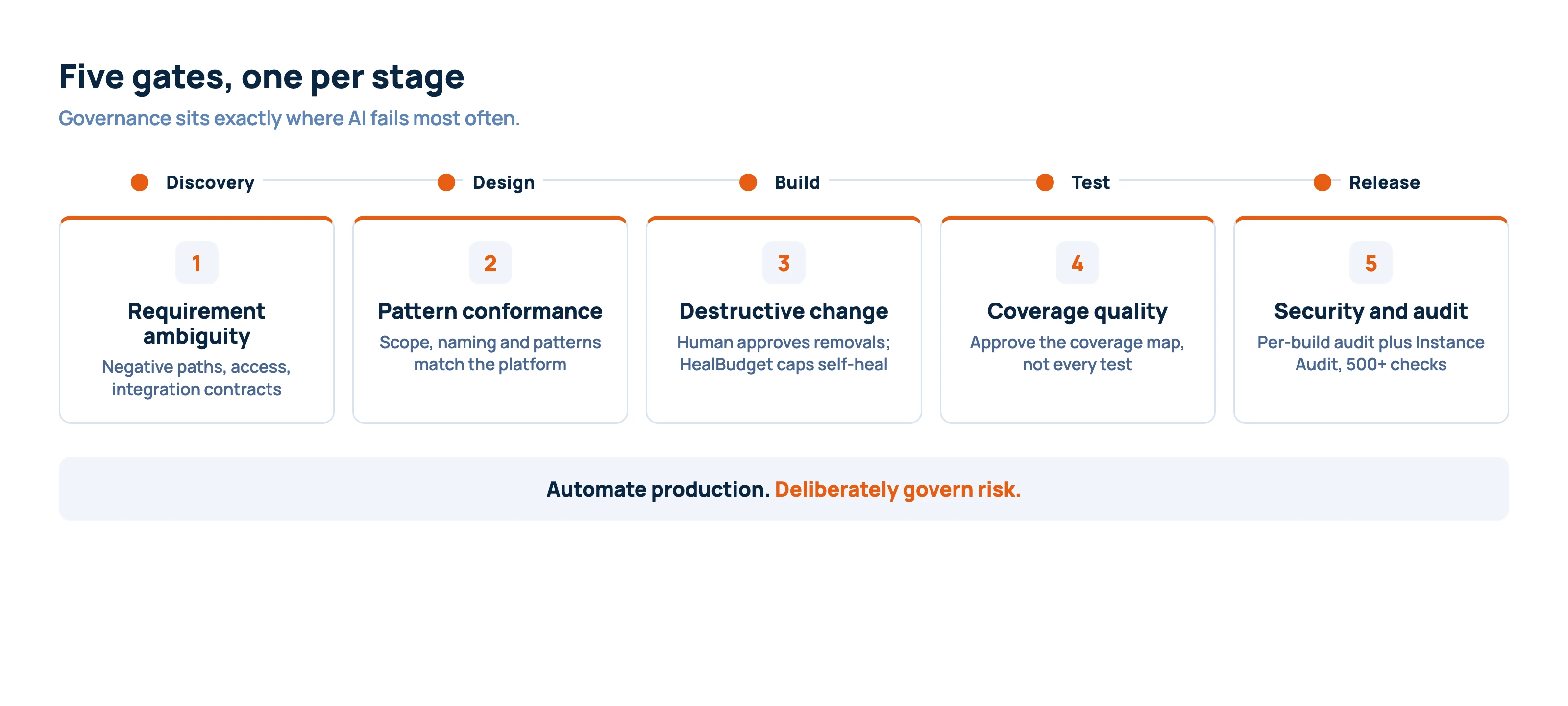
Where the Gates Need to Go
AI fails in predictable places. The SDLC should place quality gates exactly where those failures are most likely and most expensive.
- Discovery gate: requirement ambiguity. AI can draft quickly, but it cannot know what the business failed to say. The BA should confirm negative paths, exception handling, access-control assumptions, reporting needs, and integration contracts.
- Design gate: platform pattern conformance. AI can suggest plausible defaults, but the architect must apply enterprise context. This means checking scope boundaries, naming, table-extension targets, integration patterns, and performance implications against platform standards.
- Build gate: destructive and sensitive changes. Any artifact removal, ACL change, table change, or security-sensitive script should require explicit human approval. The Yeti Build Agent enforces destructive-change confirmation and controls self-healing through HealBudget, limiting remediation attempts so builds do not run away.
- Test gate: coverage quality. Generated ATF should run automatically, but humans should approve the coverage map. The right question is not “did AI generate tests?” It is “do these tests protect the process, the data, the access model, and the failure paths?”
- Release gate: security and audit evidence. Security checks, script audits, and instance-level checks should inform the release decision. The Build Agent audits each build, while Instance Audit performs broader checks across 500+ checkpoints. The release manager approves based on findings, severity, and business risk.
This is the core design principle: automate production, but deliberately govern risk.
What Should Remain Human-Led
The strongest AI-enabled SDLCs are not the ones that automate everything. They are the ones that know where not to automate.
AI should not independently approve destructive changes, security-sensitive ACLs, major data model changes, integration contracts, or production releases. These decisions carry architectural, operational, and business risk.
The goal is not to remove human approval. The goal is to make approval faster, better informed, and focused on the areas where judgment matters most.
What to Measure
Traditional delivery metrics become less useful when AI handles large parts of production work. Story points, for example, become a weaker proxy for engineering effort.
Instead, ServiceNow teams should measure quality, throughput, and the gap between AI output and human acceptance.
- Acceptance ratio. The percentage of AI-generated artifacts accepted without substantive change. A healthy range is typically 70 to 90 percent. Below 70 percent may indicate weak prompting, poor context, or missing platform patterns. Above 95 percent may suggest review is too light.
- Cycle time from brief to deploy. Measure the time from approved requirement to production-ready change. For standard-scoped items, mature teams should target days rather than weeks.
- Audit findings per release. Track findings by severity and trend them over time. Flat or declining findings indicate control stability. Spikes suggest drift in patterns, prompts, or review quality.
- Coverage by table for ACLs and ATF. For tables the team owns, coverage should be close to complete. Access control and test coverage should be visible, measurable, and reviewed.
- Rework rate. Track how often generated artifacts need to be rebuilt because the original requirement, design, or pattern was wrong. High rework is usually a signal that the front-end gates need improving.
- Defect escape rate. Measure defects that reach UAT or production despite generated tests, audits, and human review. This is one of the clearest indicators of whether the new SDLC is actually safer.
- Spend per build through HealBudget. If builds consistently hit the self-healing cap, the answer is usually not a bigger budget. It is a clearer requirement, better pattern context, or a stronger design gate.
In internal benchmarking, the underlying Yeti model is 60 percent more accurate than generic LLMs across 120+ ServiceNow-specific benchmarks. That gives teams a stronger foundation, but the operating model still matters. Accuracy improves production. Governance protects delivery.
A Practical 90-Day Rollout
AI-enabled delivery does not need to start with a full transformation. It should start with a controlled workstream, clear gates, and measurable outcomes.
- Days 0 to 30: start with assisted discovery and design. Roll out Yeti AI Chat to developers, BAs, and architects. Choose one contained workstream, such as catalog or a scoped app enhancement. Use AI to draft requirements, acceptance criteria, technical designs, and implementation options. Measure cycle time, acceptance ratio, and the quality of generated specifications.
- Days 30 to 60: pilot generated build and test. Introduce the Yeti Build Agent with two squads across 15 to 25 stories. Compare cycle time, audit findings, rework rate, and review effort against the baseline. Use this phase to refine prompt patterns, platform standards, and review checklists.
- Days 60 to 90: operationalize the gate fabric. Formalize acceptance criteria, destructive-change confirmations, security checks, audit requirements, test coverage review, and release approvals. Update release runbooks and retrain teams around review-first habits.
At this point, the organization should not just be using AI. It should have a measurable AI-assisted SDLC.
The Yeti Build Agent currently supports 42 Fluent artifact classes and has been benchmarked across 291 build stories, so this rollout is grounded in practical ServiceNow delivery patterns rather than theory.
The Mindset Shift That Matters
The core change is simple:
AI can now produce faster than humans can review.
The competitive advantage does not come from AI generation alone. It comes from redesigning review so that humans focus on risk, exceptions, architecture, and approval decisions, while automated gates handle the routine checks at scale.
Preserving a single-developer, feature-branch mindset will cap throughput. Teams need to review more like high-volume open-source projects: batch by pattern, use checklists, enforce gates, and trust consistent audit data.
Senior effort should move away from the routine 95 percent and toward the hard 5 percent: ambiguous requirements, sensitive security decisions, complex integrations, performance risks, and architectural exceptions.
Teams that make this shift will be able to support materially more throughput per senior engineer. In mature environments, a three to five times improvement is a realistic target.
The choice is becoming clear: redesign delivery around AI-assisted production and governed review, or keep the old cost structure while competitors compound the advantage.
Related Reading
What ServiceNow Projects Will Look Like in 12 Months
The shift-left model: 30/30/30/10 becomes 65/15/10/10, and the SDLC clock more than halves.
TechnicalScoped App Builds with the Yeti Build Agent
The 10-stage pipeline behind a fully audited deploy.
AdoptionPath to Value
The phased rollout we use with platform teams.
Ready to redesign your ServiceNow SDLC?
Start with one contained workstream. Measure the gap between AI output and human acceptance. Put gates where the risk is highest. Then scale what works. Start with Yeti AI Chat for free, or talk to Sales about a Yeti Build Agent pilot.